Everything in my second brain lives in one repository: Zettelkasten notes, a compiled wiki, journal entries, C++ projects, Rust libraries, Bazel build files, blog drafts. A thought and the code that proves it belong in the same place, and I have written about that before.
Obsidian, which I use to navigate the notes, only sees the Markdown half. A note about cache line alignment links to a wiki page on CPU architecture, which touches the same topic as a C++ file that implements a memory pool, which is built by a BUILD file that depends on a benchmark library. Obsidian sees two of those connections. The rest are invisible.
I built Synapse to make the whole graph visible. It crawls a repository, extracts references from every file type it understands, resolves them to concrete paths, and serves a force-directed graph over a small HTTP API. No database, no external Go dependencies. D3.js is embedded in the binary; the graph view works offline without any CDN.
What Gets Indexed
The core question for a tool like this is: what counts as a “reference”?
For Markdown files, there are two kinds: standard links [text](path) and Obsidian-style wiki-links [[note name]]. For C and C++ files, local #include "header.h" directives. For Rust, use crate::module and mod submodule declarations. For Bazel BUILD files, the deps, srcs, data, and similar attributes.
The extractor design reflects this. Each file type gets one or more Extractor implementations:
type Extractor interface {
Extract(content []byte) []RawRef
}
A RawRef is the literal text from the source file, before any path resolution. [[some-note]] in Markdown becomes RawRef{Target: "some-note", Type: EdgeWikiLink}. #include "util/math.h" becomes RawRef{Target: "util/math.h", Type: EdgeCInclude}. The extractor does not know where the file lives; it only reads bytes and returns what it finds.
The dispatch is by extension for most types, and by exact filename for cases where the extension alone is not enough:
var ByExtension = map[string][]Extractor{
"md": {markdownLinkExtractor{}, wikilinkExtractor{}},
"cpp": {cIncludeExtractor{}},
"rs": {rustUseExtractor{}, rustModExtractor{}},
"bzl": {bazelDepExtractor{}},
// ...
}
// Extension-less files need separate handling.
var ByName = map[string][]Extractor{
"BUILD": {bazelDepExtractor{}},
"WORKSPACE": {bazelDepExtractor{}},
}
The worker pool reads each file and dispatches to both maps:
for _, ex := range extract.ByExtension[ext] {
refs = append(refs, ex.Extract(content)...)
}
for _, ex := range extract.ByName[filepath.Base(path)] {
refs = append(refs, ex.Extract(content)...)
}
This turned out to be necessary because BUILD files have no extension, and a lookup in ByExtension[""] would match any extension-less file in the repository.
No Graph Database
The graph itself is a plain in-memory structure. Two maps: paths to node pointers, edge keys to edge pointers. A sync.RWMutex for concurrent ingestion.
type Node struct {
Path string `json:"path"`
FileType string `json:"file_type"`
Tags []string `json:"tags,omitempty"`
Outgoing []Edge `json:"outgoing"`
Incoming []Edge `json:"incoming"`
}
type BrainGraph struct {
nodes map[string]*Node
edges map[string]*Edge
mu sync.RWMutex
}
Each node holds its own adjacency lists. After the crawl, the graph is read-only and the API serves from it directly. For a repository of 1,500 files, this fits comfortably in a few megabytes.
The crawl itself uses a worker pool. Walking the file tree and reading files is I/O bound; multiple goroutines keep the disk busy while others wait. The workers return fileResult structs over a channel; the main goroutine collects results and adds edges to the graph after all workers finish:
jobs := make(chan fileJob, len(files))
results := make(chan fileResult, len(files))
for i := 0; i < cfg.Workers; i++ {
wg.Add(1)
go crawlWorker(cfg, jobs, results, &wg)
}
// Collect after workers close results channel
for res := range results {
for _, ref := range res.refs {
target, resolved := resolver.ResolveRawRef(ref, res.path)
g.AddEdge(graph.Edge{ Source: res.path, Target: target, ... })
}
}
Resolution happens centrally because it needs the full file tree. A wiki-link [[Rust Ownership]] needs to be matched against all indexed paths to find zettelkasten/Rust Ownership.md. The extractor only sees one file at a time and cannot do this.
Three Bugs That Only Real Data Reveals
I wrote tests for each extractor. They all passed. Then I ran the crawler against my actual repository and found three classes of errors that no unit test had caught.
C++ attributes look like wiki-links. My Zettelkasten notes contain C++ code examples in fenced blocks. A note about [[nodiscard]] as a design technique wrote it in a code block. The extractor ran the wiki-link regex over the raw bytes and added 113 edges to nonexistent nodes: [[nodiscard]], [[likely]], [[unlikely]], and one memorable [[gnu::target_clones("sse4.2,avx2,avx512f,default")]].
The fix was to strip code regions before running the regex, while preserving all newline characters so that byte offsets for line numbers stayed valid:
func stripCode(src []byte) []byte {
dst := make([]byte, len(src))
copy(dst, src)
// Replace fenced blocks and inline spans with spaces.
// Newlines are never touched, so line counts stay correct.
...
return dst
}
filepath.Ext has an opinion about book titles. The wiki-link resolver builds a lookup table of lowercase-basename-without-extension -> file path. A note titled Robert C. Martin - Clean Code.md should be resolvable by [[Robert C. Martin - Clean Code]]. It was not.
filepath.Ext("Robert C. Martin - Clean Code") returns . Martin - Clean Code, because “the extension is the suffix beginning at the last dot in the last element of the path.” The last dot in that title is the one after C. The lookup key computed from the link target was "robert c", not "robert c. martin - clean code".
The fix: try the full lowercased basename as a key first, fall back to extension-stripping only if that fails. This handles both note titles with dots and explicit [[note.md]]-style references.
Bazel labels have colons. The Bazel extractor used a regex that excluded colons from label strings: [^":]+. Bazel’s label syntax is //package:target. Every cross-package dependency was silently dropped. The fix was a regex that matches the actual label grammar rather than “everything that is not a quote or colon.”
Tags Need to Be Nodes
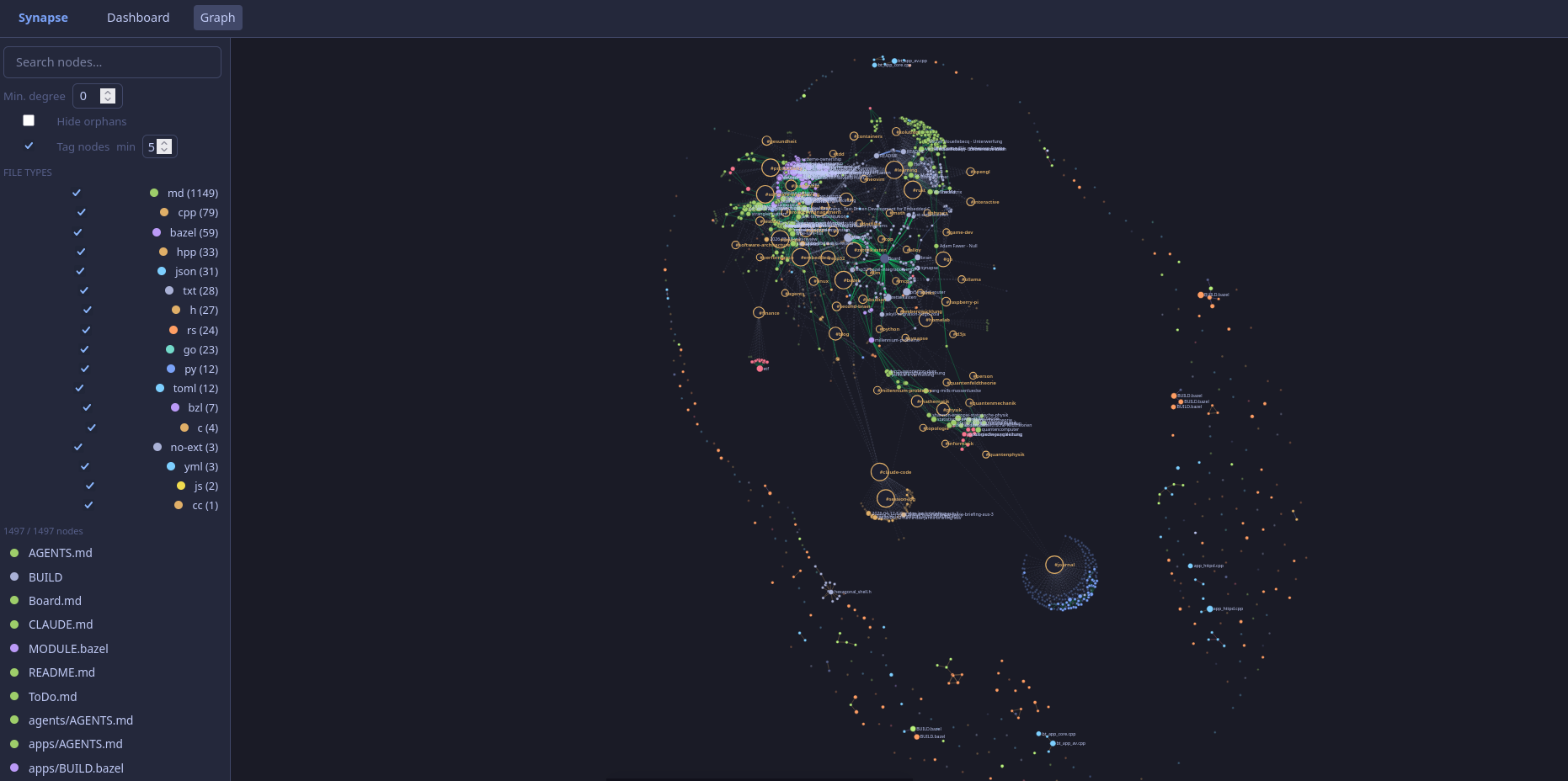
The first version of the graph rendered 1,489 nodes with a standard D3 forceSimulation. The result was indistinguishable from a scatterplot. Every node drifted away from every other node with equal force. No clusters, no structure.
The Obsidian graph, visualizing the same notes, shows clear topic regions: a dense area for #rust notes, another for #embedded, a looser cloud for #journal entries. Obsidian treats tags as nodes.
Every note with tags: [rust, embedded] has two edges in Obsidian’s graph: one to a rust node, one to an embedded node. Notes sharing tags end up near each other because they are all connected to the same anchor. The clustering is an emergent property of the graph structure, not a layout algorithm.
Synapse extracts tags from YAML frontmatter for each Markdown file and includes them in the API response. The frontend creates virtual tag nodes from the frequency map and adds note-to-tag edges to the simulation. No tag data is stored server-side beyond the tags field on each node.
The other piece is distanceMax on forceManyBody. Without it, D3’s Barnes-Hut approximation treats distant clusters as combined bodies and generates a global outward pressure that blows every cluster apart. With distanceMax(200), nodes only repel their local neighborhood and distant clusters do not interact at all. [A separate post covers the D3 physics in more detail.][d3-post]
Running against my repository: 1,082 of 1,134 Markdown files have tags, 240 unique tags, top tags are #learning (361 notes), #journal (176), #software-engineering (149), #rust (138), #embedded (123). The graph now shows these as distinct regions with overlap where topics intersect.
What It Shows That Obsidian Does Not
The most useful output is the stats.
My repository has 2,204 edges across 1,489 nodes. 699 of those edges point to files that do not exist: wiki-links to notes I referenced but have not written yet, C++ headers that are system includes, Rust crate references that resolve to external packages. These are knowingly unresolved and that is fine. But examining them surfaces planned notes, gaps in the knowledge base, and occasionally a broken link that used to point somewhere.
There are also 673 orphan nodes: files with no incoming or outgoing edges at all. Most are blog drafts and README files. Some are Zettelkasten notes that have never been linked from anywhere. Seeing them listed is useful: either they should be linked or they should not exist.
The top hub in my repository is zettelkasten/Zettelkasten Methodik.md with degree 87: 71 notes link to it, and it links to 16 others. The second is a wiki page on software architecture. These are the conceptual load-bearing nodes of the second brain, and they are not obvious when browsing the vault file by file.
The connected components count is less reassuring: 877 separate components, meaning the graph is nowhere close to a single connected whole. Most notes live in small clusters of 2 to 10 nodes with no path to the rest.
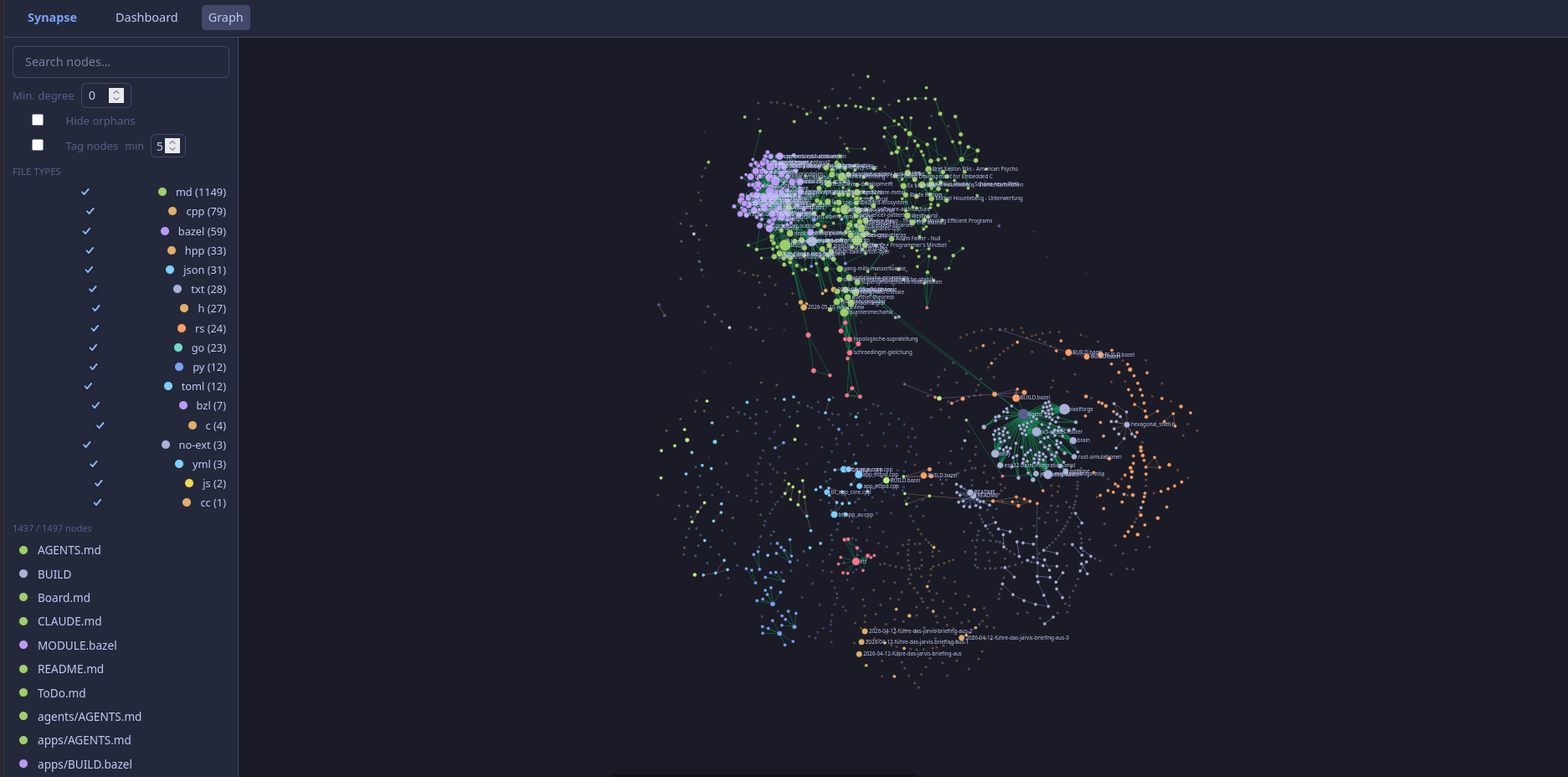
Running It
go install codeberg.org/lmilz/synapse/cmd/synapse@latest
synapse serve /path/to/repo
The server starts on port 8080. The graph view loads the full index, builds tag nodes in the browser, and lets you filter by file type, minimum degree, or search. All data lives in the Go binary at runtime; there is no configuration file, no schema, no migration.
The source is at githut.com/lmilz/synapse and codeberg.org/lmilz/synapse.